Hướng dẫn sử dụng Explore
- 1. XTABLE
- 2. CLOUD QUERY
- 2.1. Nối các tập dữ liệu
- 2.2. Xử lý các cột/trường dữ liệu bằng các hàm, thuật toán (Simple column)
- 2.3. Thêm cột/trường dữ liệu mới dựa trên điều kiện (Custom column - Case)
- 2.4. Thêm cột/trường dữ liệu mới với một giá trị cụ thể (Custom column - CONSTANT)
- 2.5. Thêm cột/trường dữ liệu mới với một giá trị cụ thể (Custom column - FUNCTION)
- 2.6. Nhóm (GROUP) dữ liệu theo cột/trường thuộc tính
- 2.7. Cấu hình lọc (FILTER) dữ liệu theo điều kiện
- 2.8. Cấu hình số lượng dòng hiển thị cho tập dữ liệu (ROW LIMIT)
- 2.9. Cấu hình sắp xếp (ORDER) hiển thị dữ liệu
- 3. IMPUTER
- 4. OUTLIER
- 5. XUNION
- 6. COLUMNAR
- 7. XCOLUMN
- 8. FORECAST
1. XTABLE
XTABLE là thuật ngữ chỉ quy trình kết hợp dữ liệu từ nhiều bảng dựa trên các cột khóa chung để tạo ra một bảng dữ liệu mới.
XTABLE là gì?
XTABLE là quá trình kết hợp dữ liệu từ nhiều bảng dựa trên một hoặc nhiều cột khóa chung. Các cột khóa này là những cột có giá trị tương đồng giữa các bảng. Các bảng dữ liệu đầu vào có thể chứa các cột khác nhau, nhưng chúng có ít nhất một cột khóa chung dùng để kết nối dữ liệu. Phép kết hợp này có thể tương tự như các phép nối (JOIN) như INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN tạo ra một bảng dữ liệu mới chứa các cột được chọn từ các bảng đầu vào, kết hợp dựa trên các cột khóa.
Quy trình tổng quát bao gồm việc xác định các bảng và cột khóa, chọn các cột cần thiết từ mỗi bảng và kết hợp các bảng dựa trên các cột khóa này. Trong đó có hai trường hợp khi tổng hợp dữ liệu:
- Trường hợp 1: Tổng hợp hai hay nhiều tập dữ liệu theo khóa chính và chỉ lấy các dòng dữ liệu theo cột khóa chính ở tập dữ liệu đầu vào.

- - Trường hợp 2: Tổng hợp hai hay nhiều tập dữ liệu theo khóa chính và lấy tất cả các dòng dữ liệu ở các tập dữ liệu.

XTABLE sử dụng như thế nào trên hệ thống?
Thực hiện trên hệ thống theo các bước hướng dẫn sau:
- Bước 1: Xác định tập dữ liệu đầu vào. Vào hệ thống chọn module Explore, chọn tập dữ liệu cần tổng hợp (Bảng 1) và chọn XTABLE.
|
|
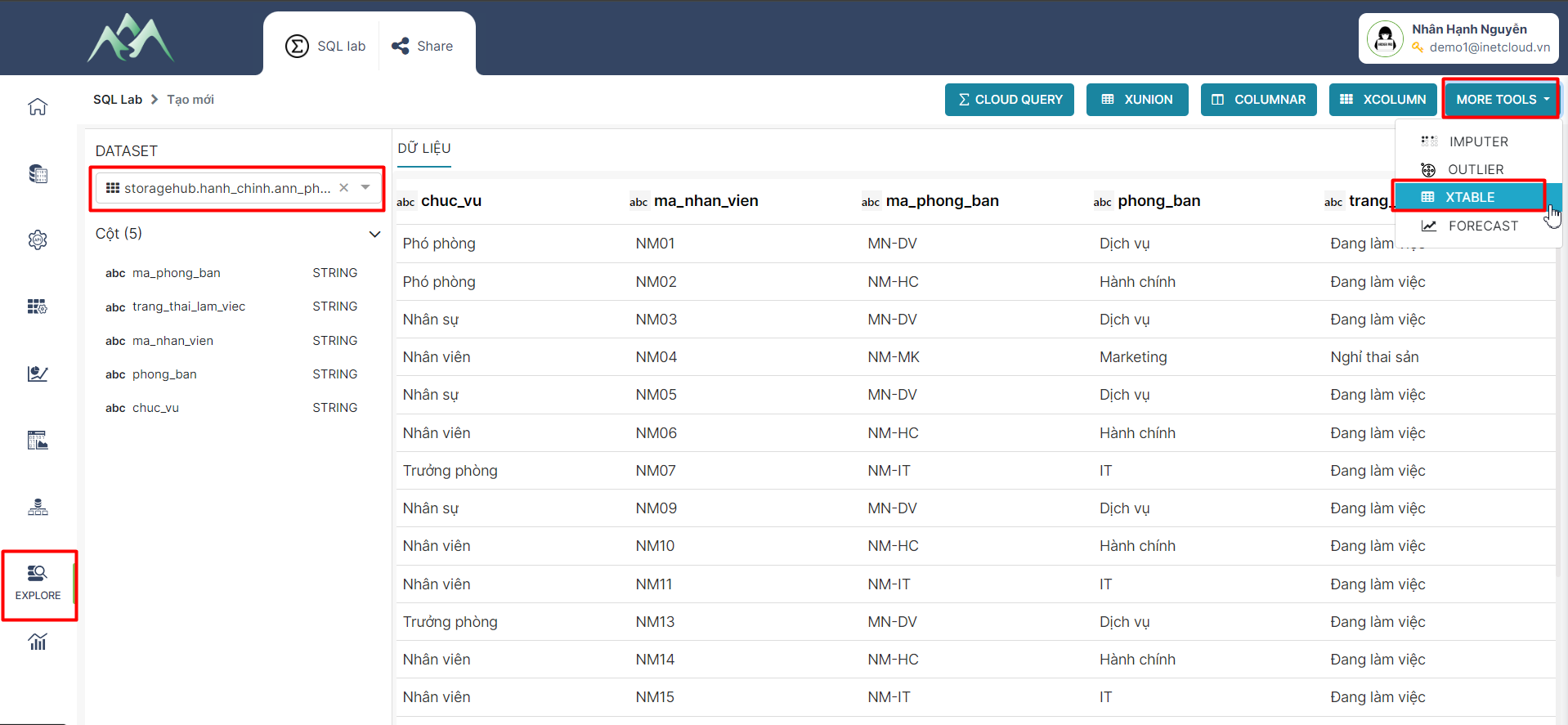
- Bước 2: Xác định cột khóa chính của tập dữ liệu đầu vào. Trên hệ thống chọn trường thuộc tính làm khóa chính. Khóa chính là điều kiện để tổng hợp các giá trị tương đồng giữa các tập dữ liệu.
|
|
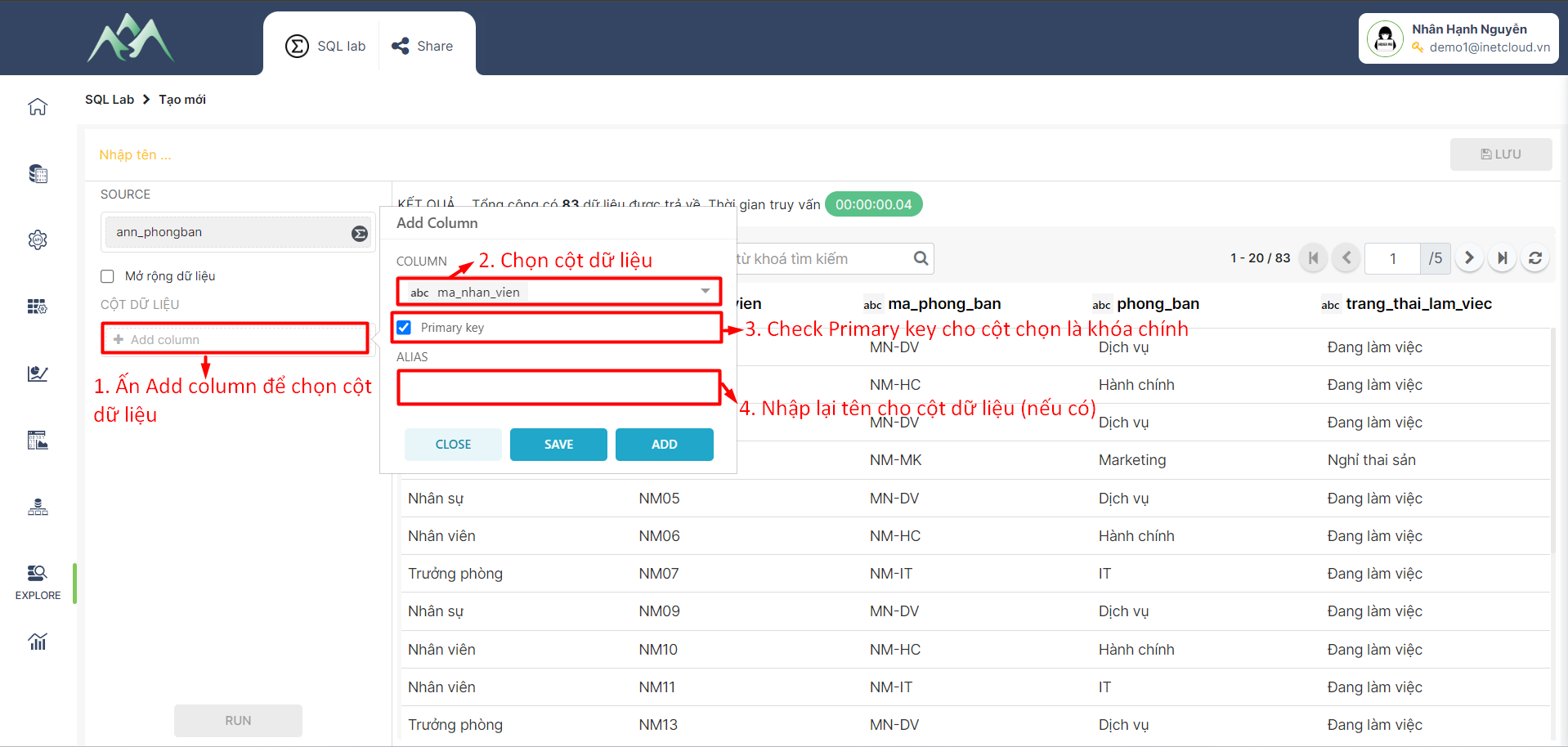
- Bước 3: Xác định các cột cần chọn từ tập dữ liệu đầu vào. Trên hệ thống chọn Add column cho tập dữ liệu XTABLE.
|
|
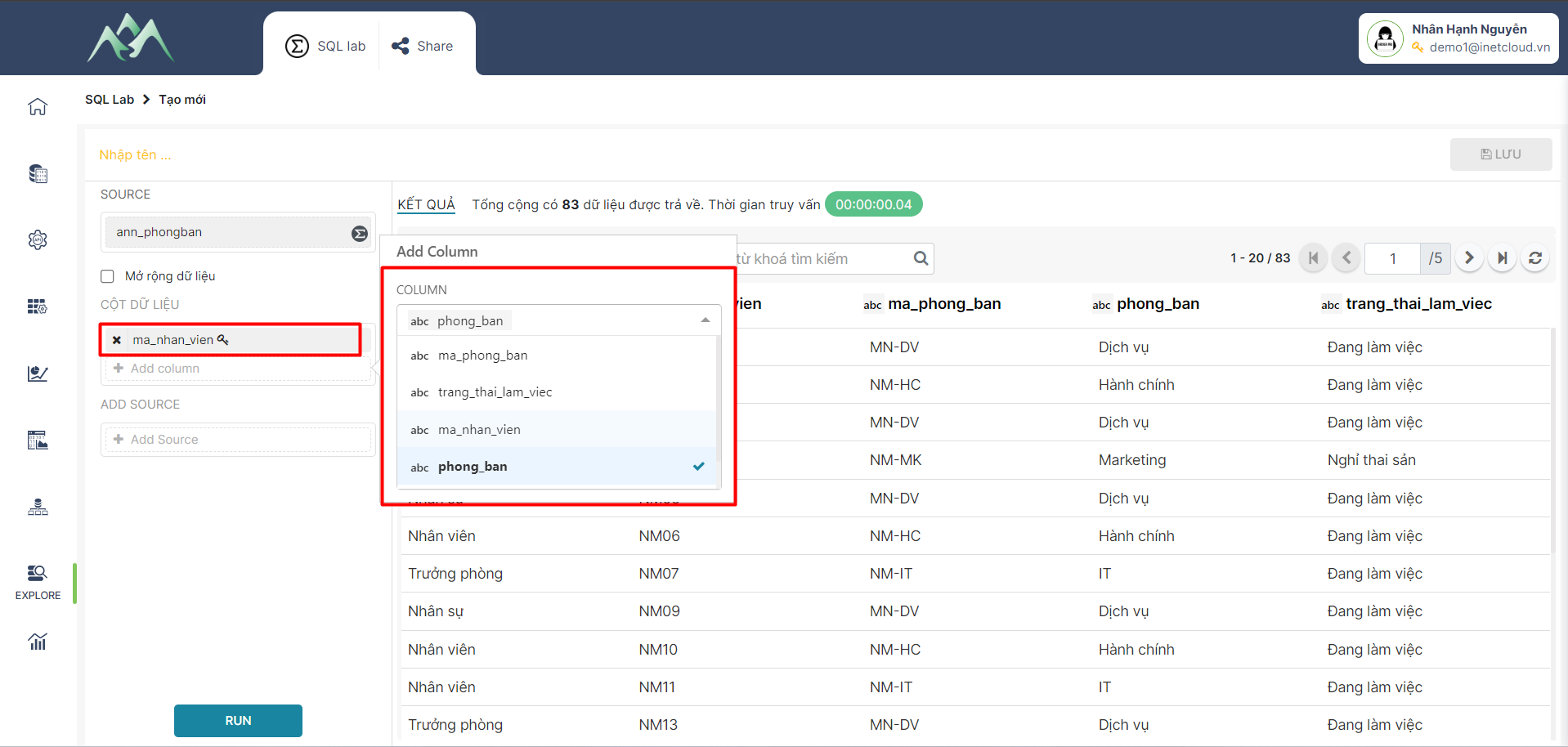
- Bước 4: Ấn ADD/SAVE để lưu cột dữ liệu vào tập dữ liệu hiện tại. Trong đó: ADD sẽ lưu và hiển thị lại giao diện để thực hiện thêm cột dữ liệu khác, SAVE sẽ lưu cột dữ liệu thêm mới và đóng bảng Add column.
|
|
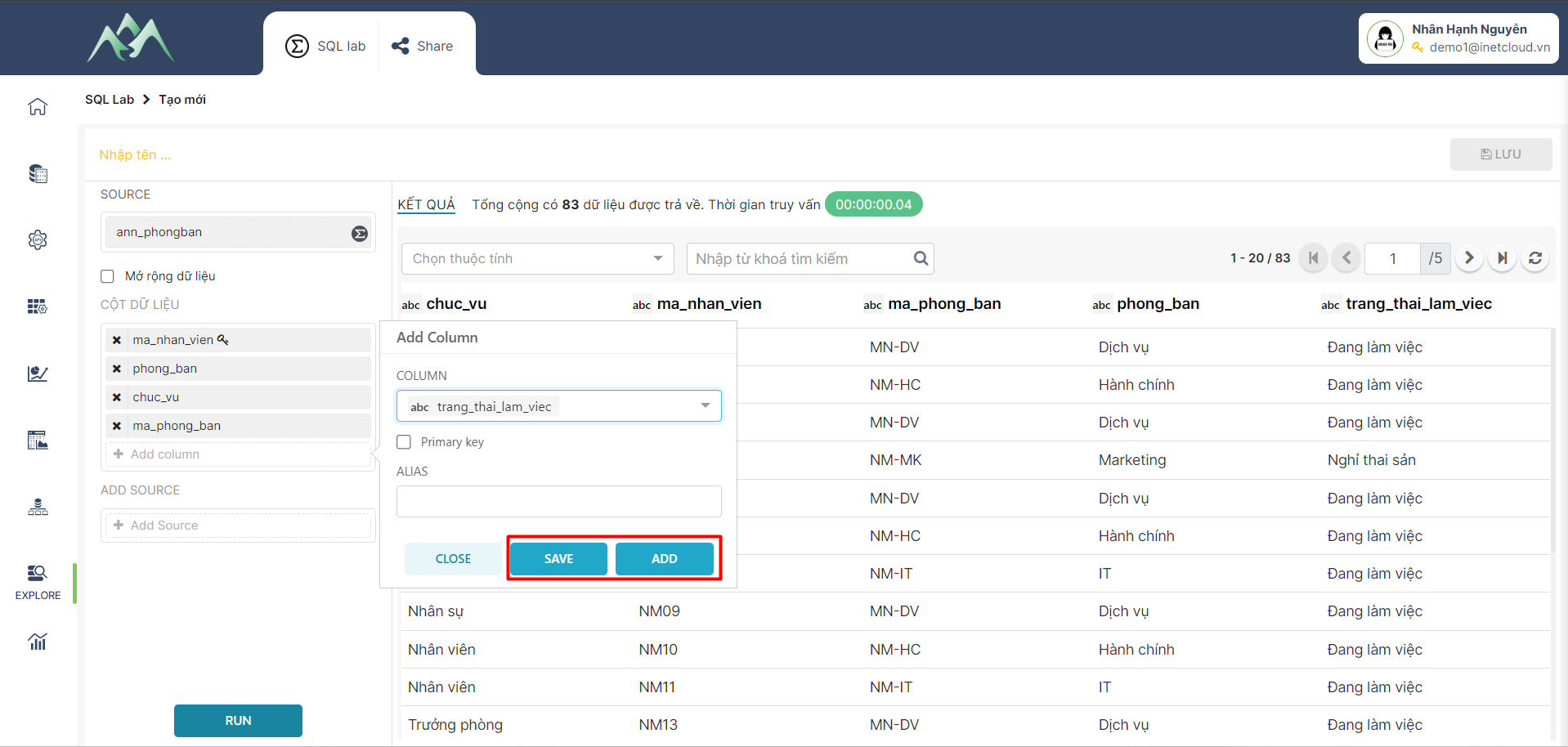
- Bước 5: Chọn tập dữ liệu cần tổng hợp (Bảng 2) với tập dữ liệu đầu vào (Bảng 1).
|
|
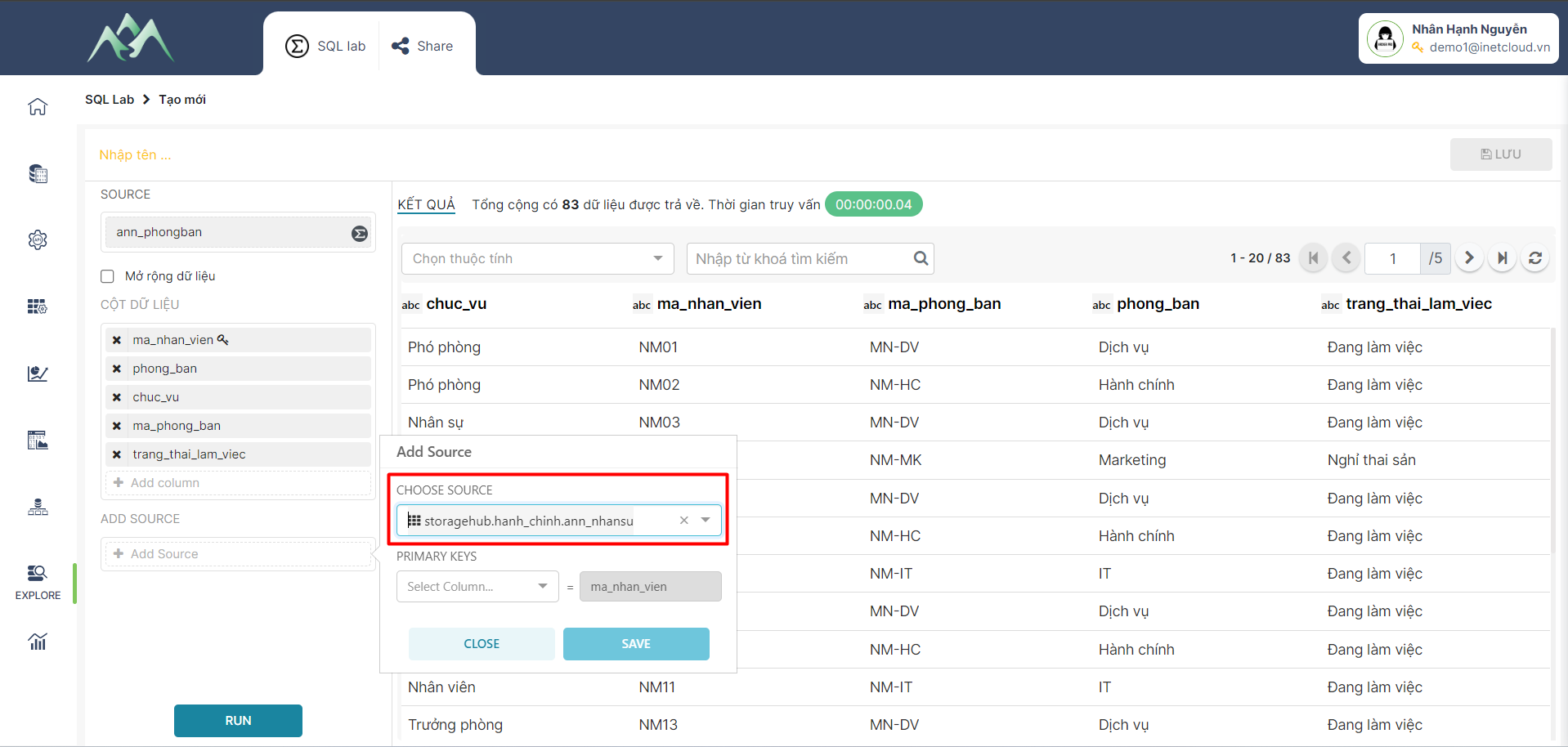
- Bước 6: Chọn trường thuộc tính của tập dữ liệu cần tổng hợp để map với tập dữ liệu đầu vào, sau đó lưu thông tin khóa chính được map.
|
|
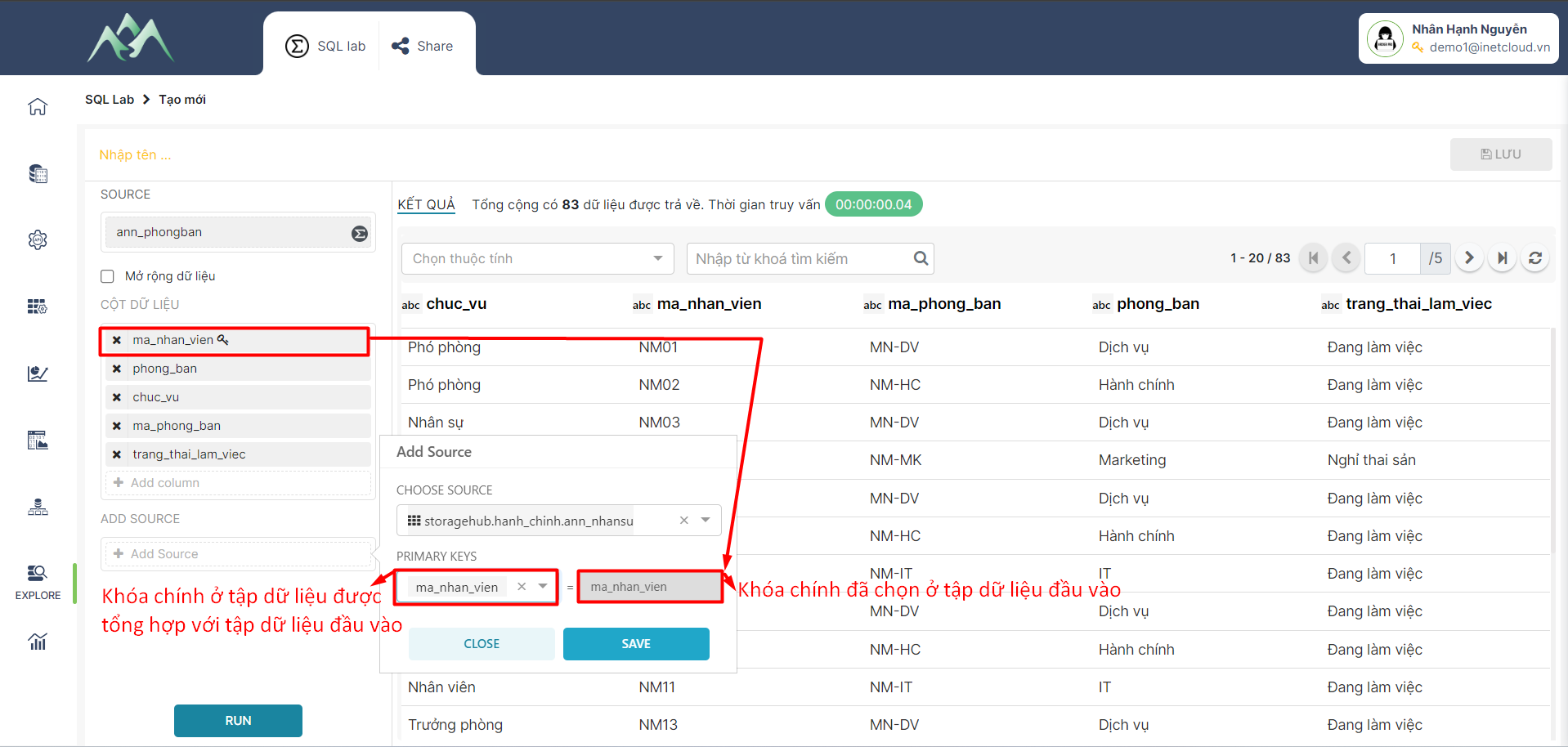
- Bước 7: ADD thêm cột trường thuộc tính dữ liệu cho tập dữ liệu đầu vào (Bảng 1).
|
|
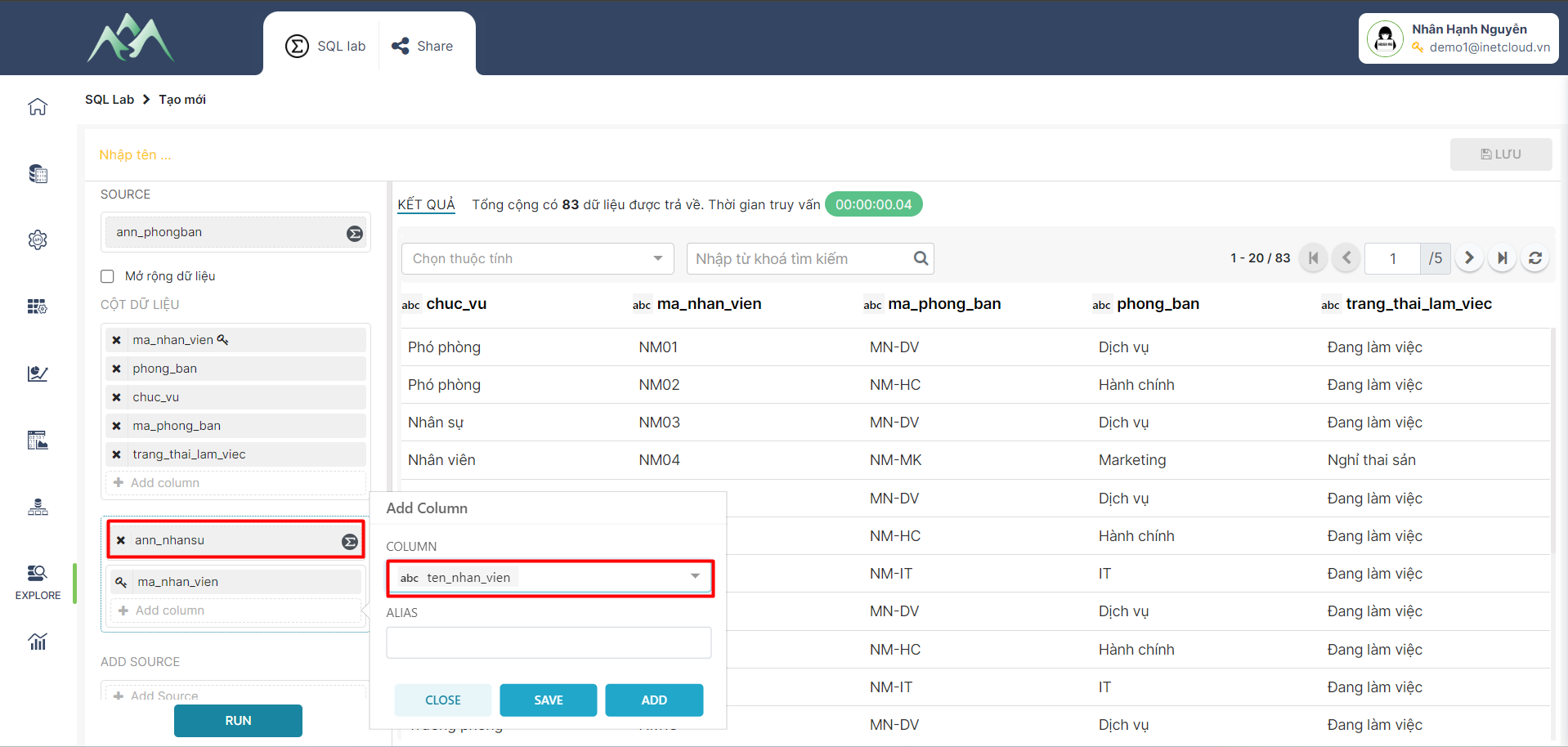
- Bước 8: Thực hiện kết hợp các bảng theo cột khóa. Trên hệ thống ấn “RUN” để xem dữ liệu được tổng hợp (Bảng 3 = Dữ liệu bảng 1 + bảng 2).
|
|
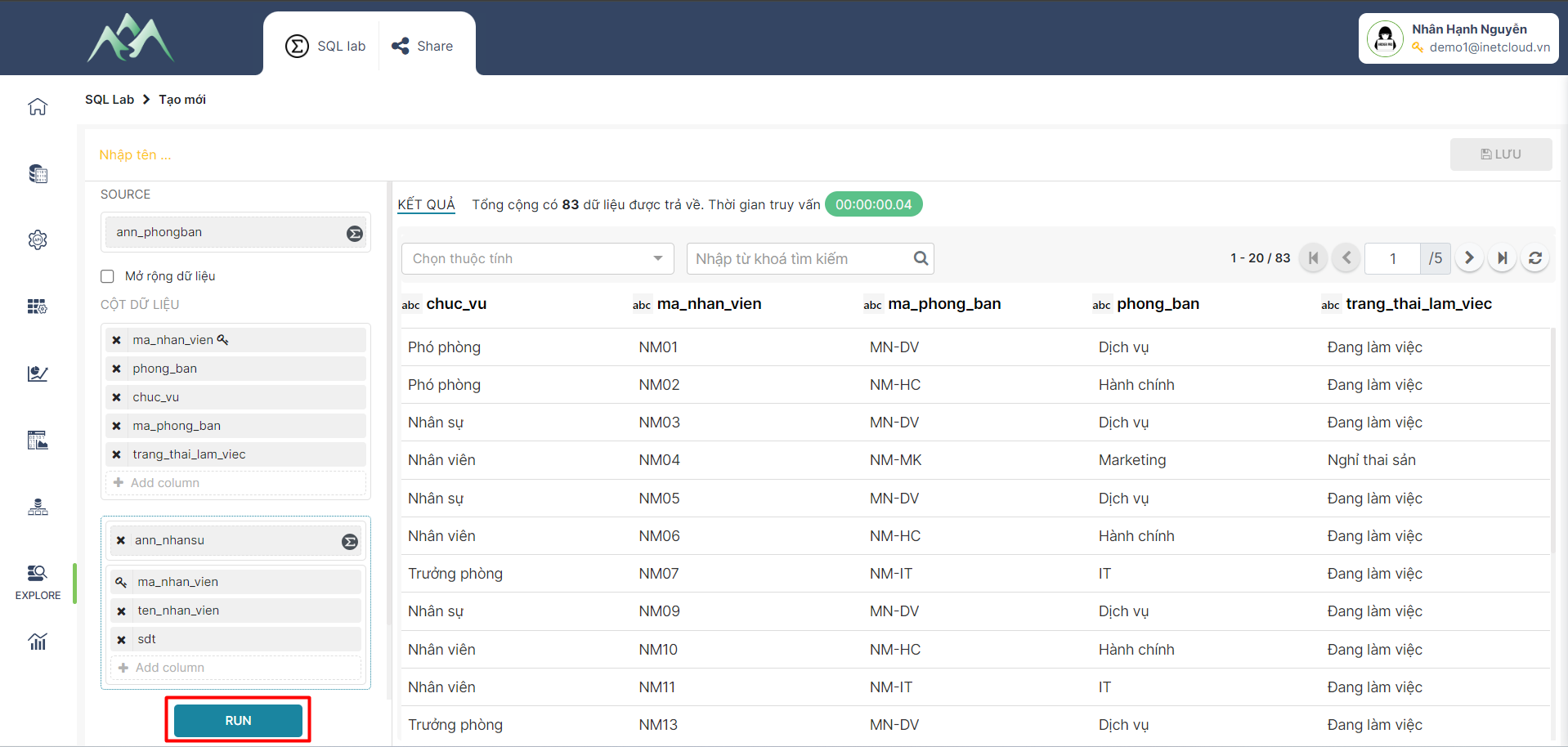
- Bước 9: Nhập tên cho tập dữ liệu mới được tổng hợp, chọn Lưu thông tin tập dữ liệu được tổng hợp bằng công cụ XTABLE.
|
|
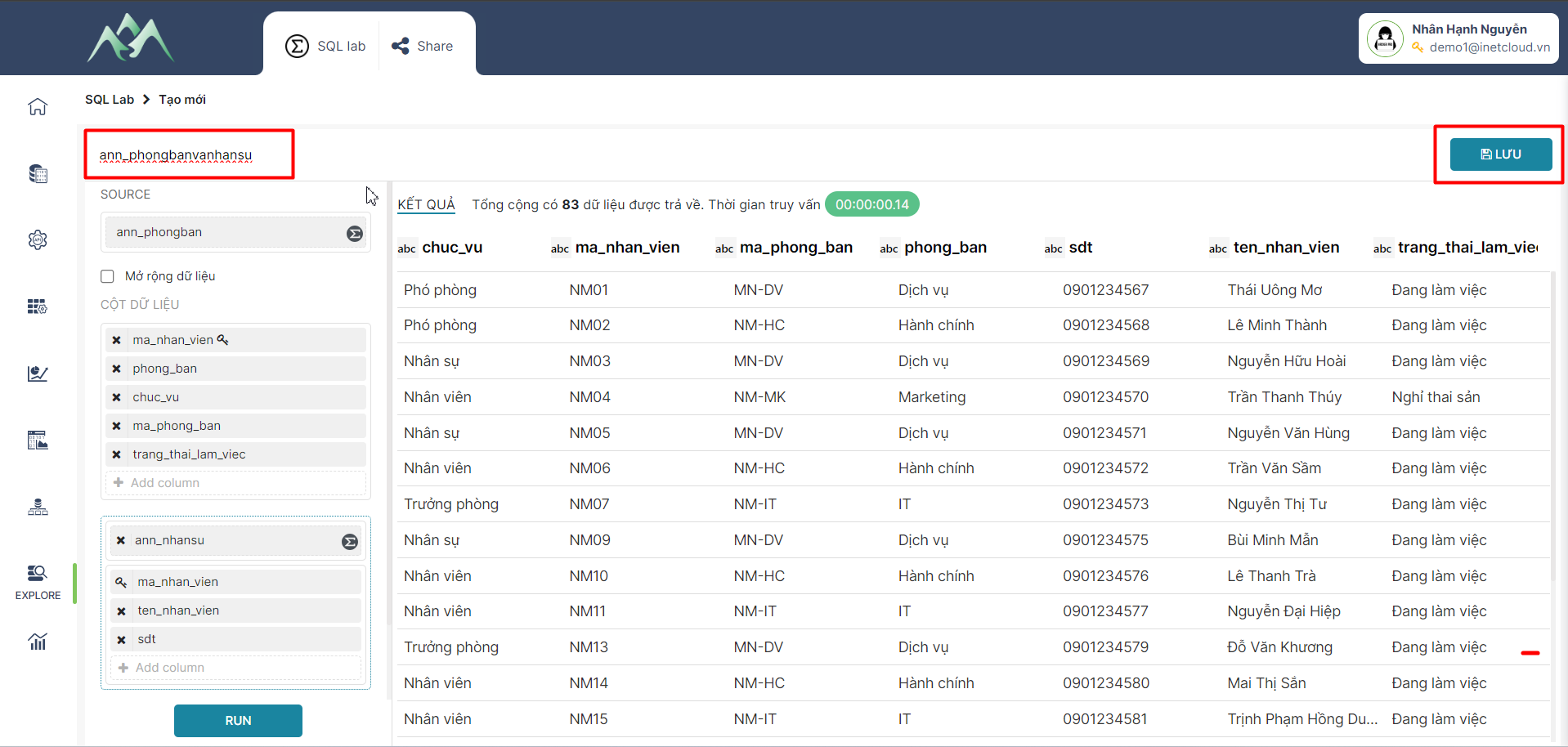
Lưu ý:
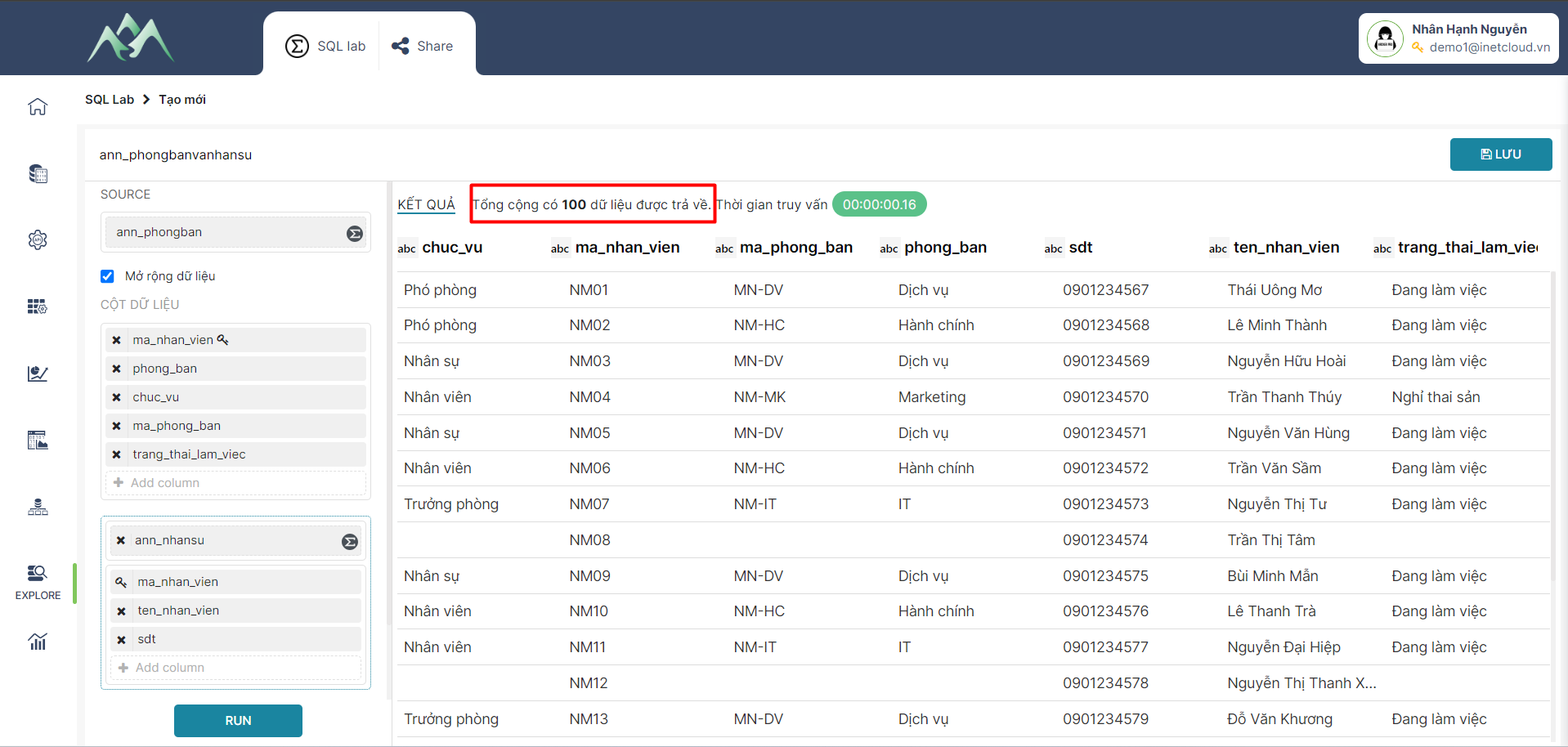
Chức năng Check/ Không check vào ô "Mở rộng dữ liệu" tương đương với 2 trường hợp tổng hợp dữ liệu như sau:
- Trường hợp 1: Check vào ô "Mở rộng dữ liệu" : Kết quả được tổng hợp từ hai hay nhiều tập dữ liệu theo khóa chính và lấy tất cả các dòng dữ liệu ở các tập dữ liệu.
|
|
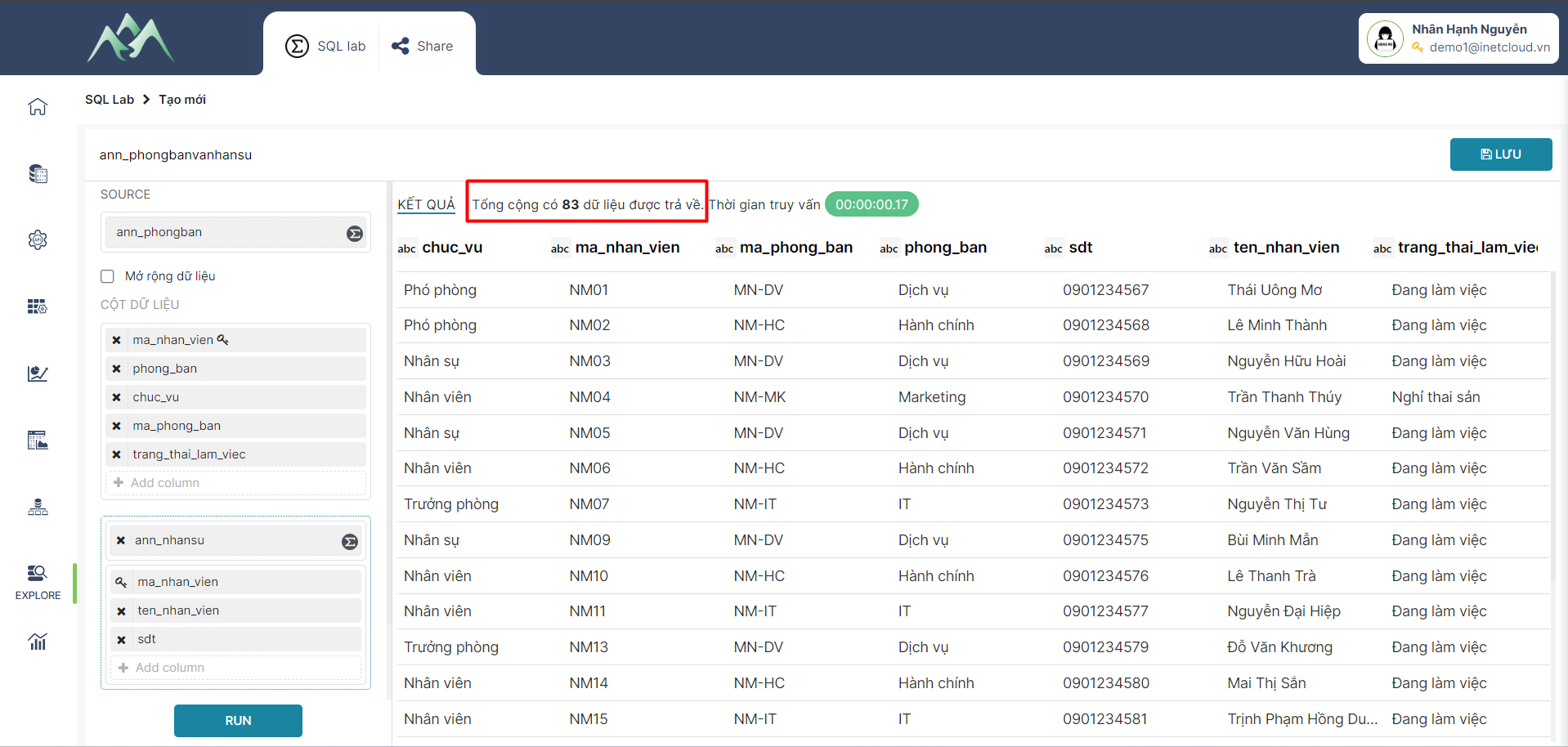
- Trường hợp 2: Không check vào ô "Mở rộng dữ liệu" : Kết quả được tổng hợp từ hai hay nhiều tập dữ liệu theo khóa chính và chỉ lấy các dòng dữ liệu theo cột khóa chính ở tập dữ liệu đầu vào
|
|
2. CLOUD QUERY
CLOUD QUERY là một công cụ mạnh mẽ để truy vấn và tích hợp dữ liệu từ nhiều nguồn khác nhau. Với các biểu thức, cú pháp truy vấn và các hàm chức năng để hỗ trợ người dùng hệ thống dễ dàng truy vấn và tích hợp dữ liệu từ các nguồn về một tập dữ liệu duy nhất, giúp tạo ra những cái nhìn toàn diện và tổng hợp về dữ liệu.
2.1. Nối các tập dữ liệu
- Bước 1: Xác định tập dữ liệu đầu vào. Trên hệ thống chọn module Explore, chọn tập dữ liệu cần tổng hợp và chọn CLOUD QUERY.

- Bước 2: Xác định tập dữ liệu cần tổng hợp với tập dữ liệu đầu vào. Cấu hình điều kiện nối các tập dữ liệu trên hệ thống.

Trong đó:
o LEFT SOURCE: Tập dữ liệu ban đầu (bảng 1) cần thực hiện kết nối với tập dữ liệu khác.
o ALIAS: Đặt tên liên kết cho các trường thuộc tính của tập dữ liệu ban đầu. Mục tiêu để sau khi nối các tập dữ liệu lại với nhau sẽ dễ phân biệt trường thuộc tính thuộc tập dữ liệu nào.

o JOIN TYPE: Chọn loại kết nối, chi tiết các loại kết nối có thể xem thêm tại "Tài liệu sử dụng Cloud query, đường dẫn https://book.inetcloud.vn/books/tai-lieu-su-dung-cloud-query "

o RIGHT SOURCE: Chọn tập dữ liệu (bảng 2) nối với tập dữ liệu ban đầu (bảng 1).
o CONDITIONS: Chọn trường dữ liệu là điều kiện để nối các tập dữ liệu. Cột điều kiện hay còn gọi là khóa chính để tổng hợp các giá trị tương đồng giữa các tập dữ liệu.

- Bước 3: Thực hiện kết hợp các bảng theo cột khóa . Trên hệ thống ấn TEST để xem kết quả dữ liệu được nối giữa các tập dữ liệu.

- Bước 4: Nhập tên cho tập dữ liệu mới được tổng hợp, chọn Lưu thông tin tập dữ liệu được tổng hợp bằng công cụ CLOUD QUERY.

Lưu ý: Để xử lý các cột/trường dữ liệu xem hướng dẫn chi tiết tại mục 2.2
2.2. Xử lý các cột/trường dữ liệu bằng các hàm, thuật toán (Simple column)
- Bước 1: Chọn các cột/trường dữ liệu cần cho tập dữ liệu

- Bước 2: Chọn hàm/thuật toán xử lý cột/trường dữ liệu được chọn

Lưu ý: Xem tài liệu theo đường dẫn https://book.inetcloud.vn/books/tai-lieu-su-dung-cloud-query/chapter/chuong-4-cac-ham-chuc-nang này để chi tiết hơn về ý nghĩa và chức năng của các hàm/thuật toán cần sử dụng.
- Bước 3: Đặt tên mới cho cột/trường dữ liệu. Hệ thống sẽ mặc định hiển thị tên cũ của cột/trường dữ liệu nếu không cập nhật tên mới.

- Bước 4: Ấn ADD/SAVE để lưu cột dữ liệu vào tập dữ liệu hiện tại. Trong đó: ADD sẽ lưu và hiển thị lại giao diện để thực hiện thêm cột dữ liệu khác, SAVE sẽ lưu cột dữ liệu thêm mới và đóng bảng Add column.

- Bước 5: Ấn TEST để xem kết quả dữ liệu

2.3. Thêm cột/trường dữ liệu mới dựa trên điều kiện (Custom column - Case)
- Bước 1: Chọn biểu thức CASE thực hiện thêm mới cột/trường dữ liệu.

- Bước 2: Chọn kiểu dữ liệu cho cột/trường dữ liệu mới.

- Bước 3: Cấu hình điều kiện để lấy dữ liệu cho cột/trường dữ liệu mới.

Trong đó:
o Bảng Add Filter (3): Cấu hình điều kiện lọc cho dữ liệu.

o Bảng Condition (2): Cấu hình giá trị tương ứng cho điều kiện lọc dữ liệu.

o Bảng CONDITIONS (1): Các điều kiện của cột/trường dữ liệu được tạo mới.

- Bước 4: Ấn ADD/SAVE để lưu cột dữ liệu vào tập dữ liệu hiện tại. Trong đó: ADD sẽ lưu và hiển thị lại giao diện để thực hiện thêm cột dữ liệu khác, SAVE sẽ lưu cột dữ liệu thêm mới và đóng bảng Add column.

- Bước 5: Ấn TEST để xem kết quả dữ liệu

Lưu ý: Để hiểu rõ hơn về các biểu thức có thể tham khảo thêm ở tài liệu này https://book.inetcloud.vn/books/tai-lieu-su-dung-cloud-query/chapter/chuong-3-bieu-thuc
2.4. Thêm cột/trường dữ liệu mới với một giá trị cụ thể (Custom column - CONSTANT)
- Bước 1: Chọn biểu thức CONSTANT thực hiện thêm mới cột/trường dữ liệu.

- Bước 2: Chọn kiểu dữ liệu cho cột/trường dữ liệu mới.

- Bước 3: Nhập giá trị cho cột/trường dữ liệu thêm mới.

- Bước 4: Nhập tên cho cột/trường dữ liệu thêm mới

- Bước 5: Ấn ADD/SAVE để lưu cột dữ liệu vào tập dữ liệu hiện tại. Trong đó: ADD sẽ lưu và hiển thị lại giao diện để thực hiện thêm cột dữ liệu khác, SAVE sẽ lưu cột dữ liệu thêm mới và đóng bảng Add column.

- Bước 6: Ấn TEST để xem kết quả dữ liệu.

2.5. Thêm cột/trường dữ liệu mới với một giá trị cụ thể (Custom column - FUNCTION)
- Bước 1: Chọn biểu thức FUNCTION thực hiện thêm mới cột/trường dữ liệu.

- Bước 2: Chọn kiểu dữ liệu cho cột/trường dữ liệu mới.

- Bước 3: Chọn hàm/thuật toán để lấy dữ liệu cho cột/trường dữ liệu mới.

Trong đó:
o Hàm now(): Dữ liệu được trả về ngày và giờ hiện tại của hệ thống tại thời điểm thực hiện.

o Hàm datetime(): Dữ liệu được trả về lấy ngày và giờ hiện tại hoặc để định dạng lại một giá trị ngày giờ.

o Hàm startdate(): Sử dụng các hàm tích hợp sẵn trong các hệ CSDL để lấy ngày bắt đầu của các khoảng thời gian khác nhau.

o Hàm truncdate(): Sử dụng các hàm có sẵn trong từng hệ quản trị CSDL để trích xuất ngày đầu tiên của tháng hoặc năm từ một ngày nhất định.

Chi tiết các hàm có thể xem ở tài liệu theo đường dẫn: https://book.inetcloud.vn/books/tai-lieu-su-dung-cloud-query/chapter/chuong-3-bieu-thuc
- Bước 4: Ấn ADD/SAVE để lưu cột dữ liệu vào tập dữ liệu hiện tại. Trong đó: ADD sẽ lưu và hiển thị lại giao diện để thực hiện thêm cột dữ liệu khác, SAVE sẽ lưu cột dữ liệu thêm mới và đóng bảng Add column.

- Bước 5: Ấn TEST để xem kết quả dữ liệu

2.6. Nhóm (GROUP) dữ liệu theo cột/trường thuộc tính
Mục tiêu của việc nhóm (GROUP) dữ liệu để nhóm các hàng có cùng một hoặc nhiều giá trị chung vào dùng một nhóm. Hàm GROUP này thường được sử dụng cùng với các hàm tổng hợp như COUNT, SUM, AVG, MAX, MIN. Thực hiện trên hệ thống theo các bước hướng dẫn sau:
- Bước 1: Tại tập dữ liệu cần thực hiện nhóm dữ liệu, chọn các cột/trường thuộc tính

- Bước 2: Ấn TEST để xem kết quả nhóm dữ liệu

Lưu ý: Để hiểu rõ hơn về các biểu thức có thể tham khảo thêm ở tài liệu này https://book.inetcloud.vn/books/tai-lieu-su-dung-cloud-query/page/25-group-by
2.7. Cấu hình lọc (FILTER) dữ liệu theo điều kiện
- Bước 1: Tại tập dữ liệu chọn cột/trường dữ liệu làm điều kiện lọc

- Bước 2: Chọn các toán tử để cấu hình cho điều kiện lọc

- Bước 3: Nhập giá trị cần lọc theo điều kiện

- Bước 4: Ấn ADD/SAVE để lưu cột dữ liệu vào tập dữ liệu hiện tại. Trong đó: ADD sẽ lưu và hiển thị lại giao diện để thực hiện thêm cột dữ liệu khác, SAVE sẽ lưu cột dữ liệu thêm mới và đóng bảng Add Filter.

- Bước 5: Ấn TEST để xem kết quả dữ liệu

2.8. Cấu hình số lượng dòng hiển thị cho tập dữ liệu (ROW LIMIT)
Mục tiêu: Giới hạn số lượng hàng (bản ghi) được trả về từ một truy vấn. Việc giới hạn số lượng hàng có thể hữu ích khi muốn lấy một số lượng nhỏ dữ liệu từ bảng lớn. Thực hiện trên hệ thống theo các bước hướng dẫn sau:
- Bước 1: Tại tập dữ liệu chọn hoặc nhập số lượng hàng dữ liệu cần xem

- Bước 2: Ấn TEST để xem kết quả dữ liệu

Lưu ý: Để hiểu rõ hơn về các biểu thức có thể tham khảo thêm ở tài liệu này https://book.inetcloud.vn/books/tai-lieu-su-dung-cloud-query/page/27-limit
2.9. Cấu hình sắp xếp (ORDER) hiển thị dữ liệu
Mục tiêu: Sử dụng để sắp xếp các hàng (bản ghi) trả về từ một truy vấn theo một hoặc nhiều cột. Thực hiện trên hệ thống theo các bước hướng dẫn sau:
- Bước 1: Tại tập dữ liệu cột/trường dữ liệu cần sắp xếp

- Bước 2: Chọn hướng sắp xếp dữ liệu

Trong đó:
o ASC (Ascending): Thứ tự tăng dần
o DESC (Descending): Thứ tự giảm dần.
- Bước 3: Ấn TEST để xem kết quả dữ liệu

Lưu ý: Để hiểu rõ hơn về các biểu thức có thể tham khảo thêm ở tài liệu này https://book.inetcloud.vn/books/tai-lieu-su-dung-cloud-query/page/26-order-by
3. IMPUTER
Mục tiêu IMPUTER: được sử dụng để xử lý các giá trị thiếu trong dữ liệu, tức là các ô dữ liệu mà không có giá trị (có thể là NaN, null, hoặc các giá trị không có ý nghĩa khác). Khi dữ liệu bị thiếu, việc sử dụng Imputer giúp điền các giá trị thay thế vào những vị trí thiếu này để có thể tiếp tục phân tích dữ liệu một cách chính xác.
Thực hiện trên hệ thống theo các bước hướng dẫn sau:
- Bước 1: Vào hệ thống chọn module Explore, chọn tập dữ liệu cần tổng hợp và tạo mới một tập dữ liệu tổng hợp từ IMPUTER

- Bước 2: Chọn cột dữ liệu để thuật toán Imputer giúp điền các giá trị thay thế vào những vị trí thiếu.

- Bước 3: Chọn thuật toán xử lý cho cột dữ liệu đã chọn.

Trong đó:
o Thuật toán nội suy (interpolation) được sử dụng để ước lượng giá trị tại các điểm trung gian dựa trên các giá trị đã biết của một tập dữ liệu.
o Thuật toán Simple được dùng để xử lý các bài toán như tìm kiếm tuyến tính, sắp xếp nổi bọt, hoặc tính giai thừa.
o Thuật toán KNN là một thuật toán dựa trên khoảng cách để phân loại hoặc dự đoán giá trị của một điểm dữ liệu mới dựa trên các điểm dữ liệu đã biết trong không gian đa chiều.
o Thuật toán Payesian là một trong những thuật toán phân loại phổ biến nhất trong học máy, đặc biệt là đối với các bài toán phân loại văn bản và lọc thư rác.
- Bước 4: “RUN” chạy test dữ liệu được tổng hợp.

- Bước 5: Nhập tên cho tập dữ liệu mới được tổng hợp, chọn Lưu thông tin tập dữ liệu được tổng hợp bằng công cụ IMPUTER

4. OUTLIER
Mục tiêu OUTLIER: giúp xác định các điểm dữ liệu không phù hợp hoặc không bình thường so với phần còn lại của tập dữ liệu.
Thực hiện trên hệ thống theo các bước hướng dẫn sau:
- Bước 1: Vào hệ thống chọn module Explore, chọn tập dữ liệu cần tổng hợp và tạo mới một tập dữ liệu tổng hợp từ OUTLIER.

- Bước 2: Chọn cột dữ liệu dữ liệu cần xác định các điểm không phù hợp hoặc không bình thường so với phần còn lại của tập dữ liệu.

- Bước 3: Chọn thuật toán để xử lý

Trong đó:
o Thuật toán Z-Scores được sử dụng để xác định các giá trị ngoại lệ trong tập dữ liệu.
o Thuật toán IQR được sử dụng chủ yếu để phát hiện và xử lý các giá trị ngoại lệ trong tập dữ liệu
- Bước 4: Điều chỉnh giá trị xác định, so sánh

- Bước 5: “RUN” chạy test dữ liệu được tổng hợp

- Bước 6: Nhập tên cho tập dữ liệu mới được tổng hợp, chọn Lưu thông tin tập dữ liệu được tổng hợp bằng công cụ OUTLIER

5. XUNION
Tổng hợp các dòng dữ liệu ở nhiều tập dữ liệu với điều kiện các tập dữ liệu cùng số lượng, cùng tên và kiểu dữ liệu của các thuộc tính ở các tập dữ liệu phải giống nhau.
Thực hiện trên hệ thống theo các bước hướng dẫn sau:
- Bước 1: Vào hệ thống chọn module Explore, chọn tập dữ liệu cần tổng hợp và tạo mới một tập dữ liệu tổng hợp từ XUNION

- Bước 2: Chọn (ADD COLUMN) các cột trường thuộc tính cần sử dụng

- Bước 3: Chọn các tập dữ liệu cần tổng hợp với tập dữ liệu ban đầu

- Bước 4: “RUN” chạy test dữ liệu được tổng hợp

- Bước 5: Nhập tên cho tập dữ liệu mới được tổng hợp, chọn Lưu thông tin tập dữ liệu được tổng hợp bằng công cụ XUNION

Lưu ý:
Nếu các tập dữ liệu nối với nhau không đồng nhất về số lượng thuộc tính, tên và kiểu dữ liệu của các thuộc tính hệ thống sẽ cảnh báo:

6. COLUMNAR
Mục tiêu COLUMNAR: Chuyển dữ liệu từ định dạng "dòng" sang "cột".
Thực hiện trên hệ thống theo các bước hướng dẫn sau:
- Bước 1: Vào hệ thống chọn module Explore, chọn tập dữ liệu cần tổng hợp và tạo mới một tập dữ liệu tổng hợp từ COLUMNAR.

- Bước 2: “COLUMN FIELD” chọn cột dữ liệu cần định dạng "dòng" sang "cột".

- Bước 3: “COLUMN VALUE” chọn giá trị cột cần tổng hợp

- Bước 4: “GROUP FUNCTION” chọn các hàm tính toán, xử lý dữ liệu cho cột giá trị cần tổng hợp.

Lưu ý:
Để hiểu và sử dụng từng hàm có thể tham khảo tài liệu chi tiết theo đường dẫn: …
- Bước 5: “COLUMN KEYS” chọn cột trường thuộc tính là khóa xử lý

- Bước 6: “IMPUTER ALGORITHM” chọn thuật toán điền giá trị thiếu.

Trong đó:
o Thuật toán nội suy (interpolation) được sử dụng để ước lượng giá trị tại các điểm trung gian dựa trên các giá trị đã biết của một tập dữ liệu.
o Thuật toán Simple được dùng để xử lý các bài toán như tìm kiếm tuyến tính, sắp xếp nổi bọt, hoặc tính giai thừa.
o Thuật toán KNN là một thuật toán dựa trên khoảng cách để phân loại hoặc dự đoán giá trị của một điểm dữ liệu mới dựa trên các điểm dữ liệu đã biết trong không gian đa chiều.
o Thuật toán Payesian là một trong những thuật toán phân loại phổ biến nhất trong học máy, đặc biệt là đối với các bài toán phân loại văn bản và lọc thư rác.
Lưu ý: Để hiểu và sử dụng từng hàm có thể tham khảo tài liệu chi tiết theo đường dẫn: …
- Bước 7: Ấn RUN để xem kết quả dữ liệu thêm mới vào tập dữ liệu.

- Bước 8: Nhập tên cho tập dữ liệu mới được tổng hợp, chọn Lưu thông tin tập dữ liệu được tổng hợp bằng công cụ COLUMNAR

7. XCOLUMN
Mục tiêu XCOLUMN: Mở rộng trường thuộc tính trong một tập dữ liệu. Người dùng có thể thêm một hoặc nhiều cột trường thuộc tính tạo thành một tập dữ liệu mới từ tập dữ liệu cũ.
Thực hiện trên hệ thống theo các bước hướng dẫn sau:
- Bước 1: Vào hệ thống chọn module Explore, chọn tập dữ liệu cần tổng hợp và tạo mới một tập dữ liệu tổng hợp từ XCOLUMN.

- Bước 2: Chọn ADD COLUMN để thêm một cột dữ liệu vào tập dữ liệu đang thực hiện.

Trong đó:
o COLUMN NAME: Tên cột trường thuộc tính cần thêm vào tập dữ liệu
o DATA TYPE: Loại/Kiểu dữ liệu cho trường thuộc tính mới
o VALUE: Giá trị của trường thuộc tính mới
- Bước 3: Ấn ADD/SAVE để lưu cột dữ liệu vào tập dữ liệu hiện tại. Trong đó: ADD sẽ lưu và hiển thị lại giao diện để thực hiện thêm cột dữ liệu khác, SAVE sẽ lưu cột dữ liệu thêm mới và đóng bảng Add column.

- Bước 4: Ấn RUN để chạy test dữ liệu thêm mới vào tập dữ liệu.

- Bước 5: Nhập tên cho tập dữ liệu mới được tổng hợp, chọn Lưu thông tin tập dữ liệu được tổng hợp bằng công cụ XCOLUMN.

8. FORECAST
Mục tiêu FORECAST: Được sử dụng để dự đoán giá trị của một biến phụ thuộc trong tương lai dựa trên dữ liệu quan sát có sẵn từ quá khứ.